Document your secrets, please

TL;DR ess automates syncing .env with env.sample⌗
It’s available here on Github.
The problem⌗
If you have a look through any software or infrastructure project you’ve worked on in the past, it won’t take long before you come across some “secrets”. Secrets are how we generally refer to things like passwords, API keys, and certificates that act as “identity”. If you have the secret to an identity, you or your systems are assumed to have that identity. Identities are authorized to do stuff like fetch data, and access APIs. Secrets are important. Most moderately complex projects contain secrets.
I’ll refer to “secrets” and “configuration” somewhat interchangeably throughout this text, since they’re often configured in the same way through environment variables.
What you’re less likely to find in many projects is information about what secrets are required by the project, what secrets should be authorized to do, and how to fetch new secrets. Where did they come from; where do they go? Is APPLICATION_SECRET base64 encoded, or is it a plain string? Is AWS_ACCESS_KEY_ID a read-only key or read-write?
There’s a good chance that project secrets come from an out-of-band process, because if your project secrets are checked into a version control repository, you’re in for a lecture from the nearest security engineer.
But there aren’t many established norms for documenting every secret or every configuration variable. I think automation can solve this problem.
High trust environments⌗
In high-trust environments, such as between employees and employers, it’s likely that an out-of-band process began with an employment contract. Employment contracts turn into company-issued devices and/or IT processes that grant keys or certificates that identify people and their devices. Your identity and commensurate company secrets are probably limited to your line of work. So if you’re a Site Reliability Engineer, your devices might be associated with an AWS IAM identity that can manipulate AWS S3/Route53/EC2/etc configurations. If you’re a “product engineer”, you probably have an SSH public key associated with a Github/Gitlab/Software forge organization that authorizes you to commit to various software repositories you’re likely to work on. You may also have an IAM role that grants access to fetch secrets used in the products you develop.
If you’re really unlucky, the out-of-band process from which secrets are derived might be a company wiki that gets updated only when the project bootstrap pain cave surpasses an unspecified, but very profound toil threshold.
Regardless of how project secrets are exchanged within an environment, it’s still necessary to document their provenance and constraints. Because invariably they’ll need to be updated, and someone better know how. If an API key is generated at a specific URL, or terraform output, which URL or terraform script should be documented. If a secret is base64 encoded JSON, that should be documented.
Just because you might get your secrets “for free” from a central source in high-trust environments, doesn’t mean they get updated for free. Updates require documentation. I’ve seen a single new environment variable knock out an entire team’s development and test environments for half a day because someone forgot to update a shared .env that lived in S3. Every new developer who pulled down the latest code had an unbootable application because their environment was missing this new and undocumented environment variable. Nobody knew what it was supposed to contain, and an empty string didn’t fix it. This sounds trivial, but I can assure you the day was unproductive for many of us while the contagion spread.
Low trust environments⌗
In low-trust environments, like open source projects, secrets and configuration often come from documented processes and procedures for self-service that live in wikis or a docs dir that rarely gets updated. Project maintainers are often directed toward URLs or CLI parameters that generate secrets or configurations in the necessary format. When you’re unlucky, you may have to get the attention of a benevolent-dictator-for-life to perform some magic incantation that grants you API access or share a special key that decrypts a seed database .sql file.
In any case, most applications won’t start without the requisite secrets and configurations. Does the application require a cryptographic salt, SMTP password, or API key to an external service? Do developers share keys, or does everyone generate their own? There’s often no way to tell without reading documentation in some far-flung wiki, or more likely by bothering another active developer who might remember how they did the thing 8 years ago in a fever dream.
Solving the problem⌗
In my experience in both high and low trust environments, it’s rare to find comprehensive secrets documentation.
Start by separating the act of documenting secret content from the act of documenting secret existence and provenance. Don’t confuse the need for content secrecy with the idea that secrets can’t be documented. Just because the content of APPLICATION_SECRET must remain secret, doesn’t prevent one from documenting that it must be set and how it can be retrieved or generated.
Thankfully, over time, software development has gravitated toward separating configuration from application code. Gone are the days of super_sekrit_database_password directly embedded within application code. Today, most secrets and application configuration come from environment variables. Heroku popularized this code-configuration separation in their rather oddly named 12-Factor methodology, though they were hardly the first to do so.
.env files⌗
The existence of .env files is not exactly the solution, but they do head us in the right direction.
Code-configuration separation has lead many projects to gravitate toward .env files that live at the top-level of projects. Env files are typically very dense and contain exciting stuff like:
APPLICATION_SECRET=My very eager mother just served us nine pizzas
POSTGRES_PASSWORD=AB7f6nruhpS8
...
Env files are for machines, and generally void of any documentation. Utilities like oh-my-zsh’s dotenv plugin and other similar utilities make it dirt-simple to automatically load project secrets into your environment env when .env files are present.
But where do .env files come from? They can’t be committed to revision control. That would possibly leak secrets to parties that should not be privy to our secrets. Sometimes .env files are hand-crafted every time a new person is hired or joins a project. If you’re lucky, .env files might live encrypted in a private object store bucket and fetched with a company secret like an IAM identity with a role granting access to an S3 bucket.
Regardless of where they come from, .env files are where the documentation happens. They should explain everything that is germane to every secret in the .env file; this comes in handy when we create the env.sample file. But at the same time, .env should be in .gitignore so as not to “leak” the secrets.
The .env file should contain enough documentation that it can be recreated from scratch.
env.sample files⌗
Env sample files are where our secret and configuration documentation lives in revision control. They should be generated and checked into revision control in an automated manner every time .env changes. env.sample files are for humans, not machines, and they should look something like this:
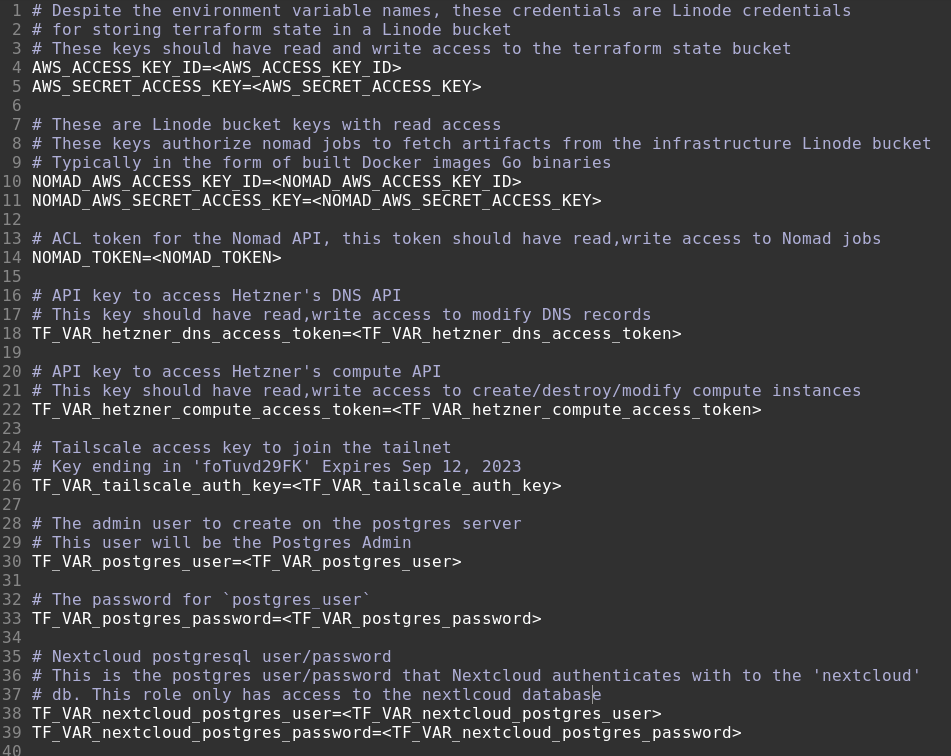
Aside: This is not the best sample file example, as it was written by me, to me. If it was written for others, I would document how/where to generate each secret.
Sample files are especially useful when no out-of-band credentials can be shared with developers. Through .env file comments, sample files are able to document not only where to retrieve secret values, but which configurations and secrets are required by projects, along with sensible defaults and example values.
Automating sample generation prevents developers from adding MY_NEW_FEATURE_SETTING to .env as a required project configuration without documenting it. When developers add new variable to .env, env.sample is updated and visible during code review, which is likely to trigger questions like, “what does this new env var do and how do developers set it?”.
At worst, env.sample will include MY_NEW_FEATURE_SETTING=<MY_NEW_FEATURE_SETTING> – letting others know of its existence – and at best, if the developer is responsible and documents why they added this new setting, env.sample reads as follows:
# This variable toggles "My new feature" on or off. To enable it, set it to `enabled`, otherwise it will be disabled
MY_NEW_FEATURE=disabled
When no out-of-band credential sharing is possible env.sample should be copied to .env when starting development on new projects
ess utility⌗
I created ess to solve this problem. While I think it works great, I encourage you and your team to automate env.sample generation in whatever way you see fit. I use ess on every one of my projects today.
ess can be run manually or as a pre-commit hook, ensuring that any time .env changes, the change is documented in the form of an updated sample.
Using it with projects is as simple as running ess install in any git repository, activating the pre-commit hook.
It also supports custom example values, e.g.
Given the following .env
FOO=My secret foo
Run with ess install --example=FOO="Fetch your own foo values from https://example.com/foogen"
Results in the following env.sample upon next commit:
FOO=Fetch your own foo values from https://example.com/foogen
This automated process brings secrets documentation somewhat more “in-band” by documenting directly within the repository at a known location: env.sample.
Document your secrets, please. Not their content.
If you have any feedback, comments, or corrections, feel free to reach out to me at hello@thisdomain.